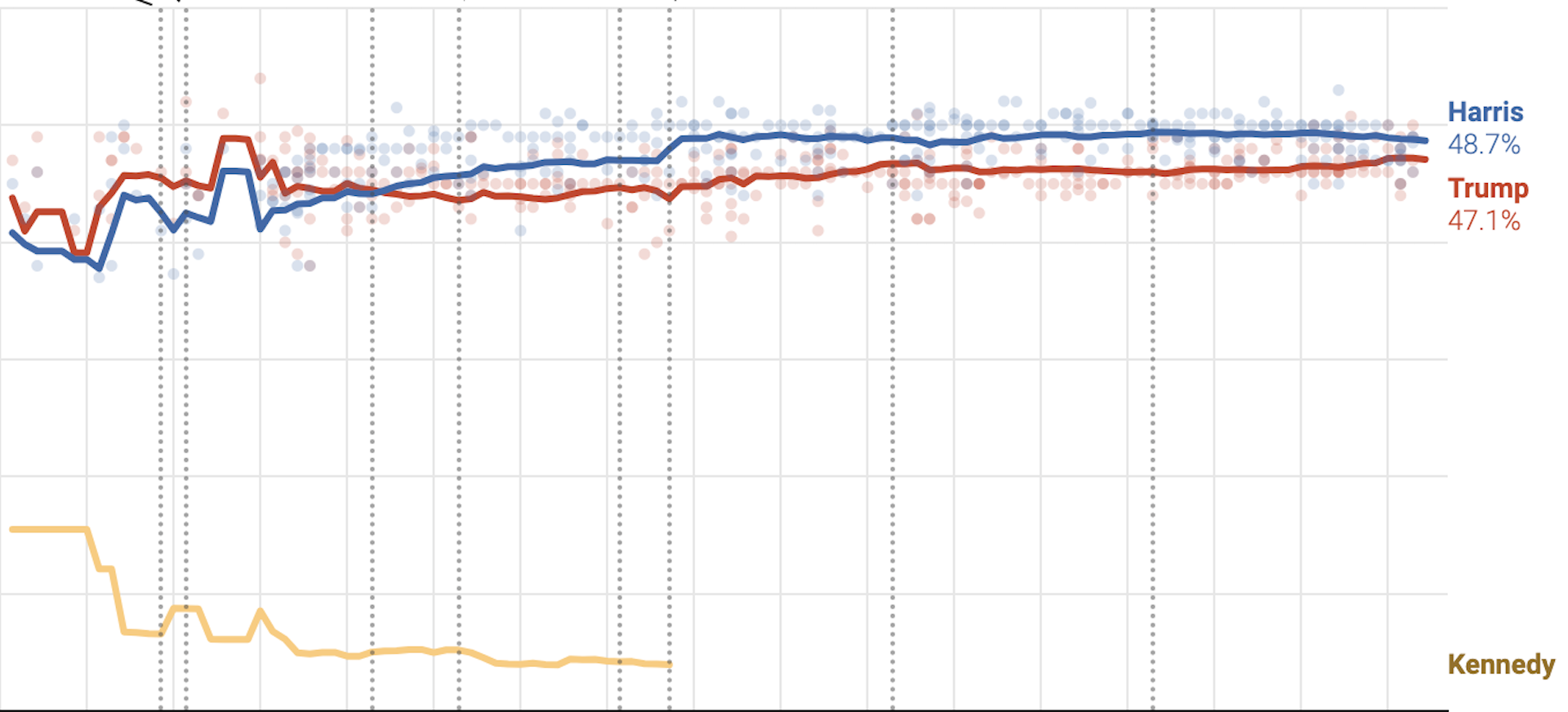
We are less than two weeks out from the 2024 presidential election, and it's time to take stock of the race.
As regular readers of Defector are certainly aware, I have spent the last few months using my proprietary prediction model, which was first created to project Tom Brady's weekly levels of crud, to forecast the outcome of the upcoming election. The model has told a clear story for the last few weeks: This election is a tossup. The current state of play poses a clear problem, however. If the election is a tossup, and the model can't offer any insight other than to forecast the race with a 50-50 chance to break in either direction, then how do I get people to pay attention to me?
Thankfully, a fellow member of the election forecasting community, Nate Silver, has published a piece in The New York Times that clearly explains why people should continue to give me lots of attention and money despite being unable to provide them with any meaningful prediction.
Silver's model, like mine, currently forecasts the race as a tossup. But what Silver understands, like me, is that the model can only tell you so much. If one is to have a full understanding of how the election might turn out, they must consider other factors, such as the underlying fundamentals, or the gut feeling of the model's creator. As Silver reveals in the Times, his gut feeling, like mine, is that Donald Trump will win the election.
It is also important to understand, however, that our gut feelings about the election should not be taken seriously. That is why Silver's piece in the Times has such a smart and explanatory headline: "Here’s What My Gut Says About the Election, but Don’t Trust Anyone’s Gut, Even Mine." As Silver eloquently explains, there is no potential outcome in this election that would give anyone reasonable cause to doubt his prediction model. His model, like mine, is currently forecasting the race as a 50-50 toss-up:
But I don’t think you should put any value whatsoever on anyone’s gut — including mine. Instead, you should resign yourself to the fact that a 50-50 forecast really does mean 50-50. And you should be open to the possibility that those forecasts are wrong, and that could be the case equally in the direction of Mr. Trump or Ms. Harris.
But it also understands, like mine, that the possibility of either candidate achieving a narrow victory is just as likely as one of them winning in a landslide:
Here’s another counterintuitive finding: It’s surprisingly likely that the election won’t be a photo finish.
With polling averages so close, even a small systematic polling error like the one the industry experienced in 2016 or 2020 could produce a comfortable Electoral College victory for Ms. Harris or Mr. Trump. According to my model, there’s about a 60 percent chance that one candidate will sweep at least six of seven battleground states.
It's refreshing to encounter an expert explaining the true state of the race so succinctly: There is a 50-50 chance that either candidate will win the election by a close margin, thus validating what the prediction models have been saying for weeks, but there is also a 60-percent chance that either candidate will win the election in a landslide, which would also validate what the prediction models have been saying for weeks. To put it more succinctly: No matter how this election pans out, nobody is allowed to say that the forecast was in any way inaccurate.
Despite how clear and definitive this explanation is, I understand that it may leave some of my particularly small-brained readers with some questions. Such as: If it is necessary for Nates such as myself and Mr. Silver to routinely mount preemptive and wonky defenses of our prediction models' accuracy, in such a way that heads off any potential avenues of criticism about the models' obvious inability to tell readers anything useful about what may or may not happen, then have we not built for ourselves a cage? Are I and all of the other election forecasters who have created this hothouse industry not trapped in an endless, low-grade tantrum, in which we continue to create an essentially valueless product while repeatedly concocting strained and defensive justifications for that product's continued existence? If the only conclusion that can be offered by any of our forecast models is, All things are equally possible, is it necessary for us to even bother creating these models at all?
These are good questions, to which I offer the following answer: Though it is obvious that the only real truth Nate Silver's model, and mine, can tell you is that election forecasts are inherently contingent and limited, to such a degree that they can offer no meaningful prediction about how a race might turn out, producing these models remains the best way to get people to pay attention to us, and therefore we have to keep doing it, because we really like attention.
As always, thank you for reading. Tomorrow, we will be publishing our latest update to the Defector Election Forecast, which will only be available to subscribers.